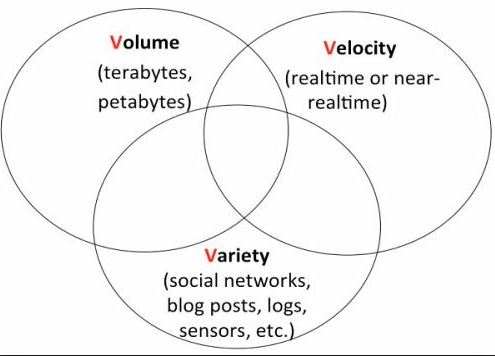
Big Data as word describes is large set of data which has many bottlenecks related to its :
–Finds insights from complex, noisy, heterogeneous, longitudinal, and voluminous data
–It aims to answer questions that were previously unanswered
In our existing traditional approach, we use a Data-warehouse to store data (OLTP-OLAP) in structured format. Process it , do data mining and build reports for further high level analysis.
This approach works fine with those applications that process less volume of data which can be accommodated by standard db servers, or up to the limit of the processor that is processing the data. But when it comes to dealing with huge amounts of scale-able data, it becomes a problem to process it using this tradition approach.
This is when Big Data got Distributed System into picture. It most of all related to Map-Reduce technology.
For example, 1 machine with 4 I/O channels can process 1 terabyte of data in approx 42 mins if the channel speed is 100 mb/s.
But if we have a distributed system of 100 machines, each with 4 I/O channels, and each channel speed is 100 mb/s, then it will take few sec to process the data.
To adopt distributed System, Map reduce algorithm was used.This algorithm divides the task into small parts and assigns them to many computers (cluster), and collects the results from them which when integrated, form the output data-set.

Using the above solution, Doug Cutting and his team developed an Open Source Project called HADOOP. Its written in java that allows distributed processing of large data-sets across clusters of computers using simple programming models. The Hadoop framework application works in an environment that provides distributed storage and computation across clusters of computers. Hadoop is designed to scale up from single server to thousands of machines, each offering local computation and storage.
Challenges with Hadoop :
Hadoop is not suitable for On-Line Transaction Processing workloads where data is randomly accessed on structured data like a relational database.Also, Hadoop is not suitable for OnLine Analytical Processing or Decision Support System workloads where data is sequentially accessed on structured data like a relational database, to generate reports that provide business intelligence. As of Hadoop version 2.6, updates are not possible, but appends are possible.
To proceed further and understand Hadoop Architecture, please read my Next Blog
- Storage
- Transfer
- Sharing
- Analysis
- Processing
- Visualization
- Security
–Finds insights from complex, noisy, heterogeneous, longitudinal, and voluminous data
–It aims to answer questions that were previously unanswered
In our existing traditional approach, we use a Data-warehouse to store data (OLTP-OLAP) in structured format. Process it , do data mining and build reports for further high level analysis.
This approach works fine with those applications that process less volume of data which can be accommodated by standard db servers, or up to the limit of the processor that is processing the data. But when it comes to dealing with huge amounts of scale-able data, it becomes a problem to process it using this tradition approach.
This is when Big Data got Distributed System into picture. It most of all related to Map-Reduce technology.
For example, 1 machine with 4 I/O channels can process 1 terabyte of data in approx 42 mins if the channel speed is 100 mb/s.
But if we have a distributed system of 100 machines, each with 4 I/O channels, and each channel speed is 100 mb/s, then it will take few sec to process the data.
To adopt distributed System, Map reduce algorithm was used.This algorithm divides the task into small parts and assigns them to many computers (cluster), and collects the results from them which when integrated, form the output data-set.

Using the above solution, Doug Cutting and his team developed an Open Source Project called HADOOP. Its written in java that allows distributed processing of large data-sets across clusters of computers using simple programming models. The Hadoop framework application works in an environment that provides distributed storage and computation across clusters of computers. Hadoop is designed to scale up from single server to thousands of machines, each offering local computation and storage.
Challenges with Hadoop :
Hadoop is not suitable for On-Line Transaction Processing workloads where data is randomly accessed on structured data like a relational database.Also, Hadoop is not suitable for OnLine Analytical Processing or Decision Support System workloads where data is sequentially accessed on structured data like a relational database, to generate reports that provide business intelligence. As of Hadoop version 2.6, updates are not possible, but appends are possible.
To proceed further and understand Hadoop Architecture, please read my Next Blog


{kind=link}